With the recent revamp of texture extraction/projection and photo modeling techniques rippling through the industry (and a general thirst for more information), the amount of photographs coming back from the set has increased steadily over the past couple years. Since having an abundance of data is a crucial requirement to set up a deep learning problem, I’ve been thinking recently about other tricks you might be able to do with deep learning to take advantage of all these photos.
One idea that came to mind was this: Often different shots in the same sequence are shot hours or days apart, and the lighting needs to be cheated closer together in comp or DI to improve continuity of the cut. But if you already happened to have a couple thousand photographs of the set from each day, why not use this as a training set for an image translation problem?
To get myself training data to run this experiment with, I went out into the neighborhood and started exploring the options. Eventually, I found a small statue at a Buddhist temple which had a nice pool of light cast on it during sunset, this was perfect because I could get angles all around the statue within about three minutes just by walking back and forth waving the camera around randomly in video mode. After a couple visits during different times of day, and nearly getting kicked out by local monks who were suspicious of my odd photography technique, I had 12,000 samples of data to play with!


All of the experiments I’ve done so far in deep learning could be considered supervised learning due to the fact that an explicit X and Y pair could be provided as examples for the network to learn from. However, due to the stochastic nature of on set photos, this case is different. There might be a couple photos from the exact same angle, however, most are just whatever handheld shots you can get when the right moment rolls around. As long as the two sets of photos are a matching distribution, this is still enough information for a human to understand the differences and make creative decisions with the data, and possibly enough for an unsupervised learning algorithm to do the same.
Many recent papers on unsupervised image translation propose architectures which I thought might be able to solve this problem, UNIT, DiscoGan and CycleGan are just a couple examples. My first instinct was that a CycleGan would have a good chance, however, after I had the network built I found that it didn’t train very stable with this set of images. It would get a small subset of images to be able to convert, like the statue’s chest for example, but then everything else would be noisy garbage. I think the fact that I waved the camera around freely, sometimes capturing up angles with the sky in the background, other times looking down toward the ground, might have created too wide of a domain for it to easily build a relationship between.
Since I’d already invested the time to get the network running, I figured why not spend a couple days screwing around with the architecture to see if I could save it from the trash bin, and it actually paid off. What ended up getting it working was a combination of two things, serving images with a similar perspective to the networks (found using features from a Resnet34 to measure cosine similarity between the two sets), and penalizing the difference in mean and standard deviation between real and fake images within the discriminator’s features.
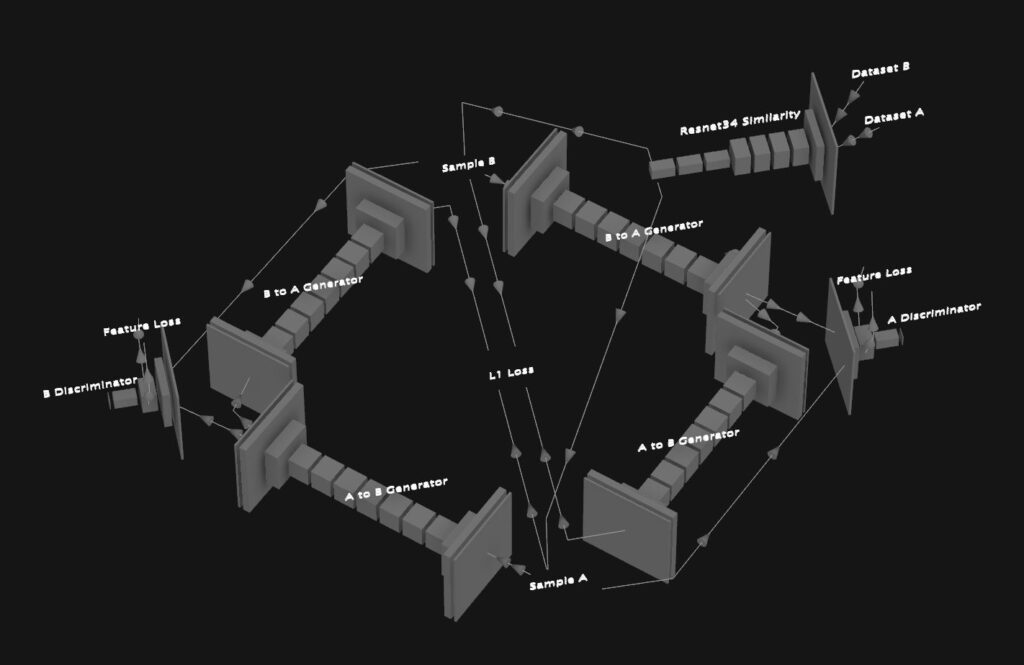
As the network trained, it evolved in an interesting way, starting by kind of replicating the input image with a color correction, and then slowly dividing up into separate corrections for separate areas of the image, and eventually building to more complex things like erasing the shadow off the roof behind the statue and painting in the shadow underneath the statues chin. After about two days of training, here is the level it ended up at:


By the time this finished up I had managed to gather a dataset of another statue, so I chucked it into the network to see how well another scene functioned. At first, it didn’t really work, it would translate properly in one direction but produce garbage going the other way, however, after adjusting the threshold for the cosine similarity used to pair the input images, it also began to produce a coherent result.


Although I may need to employ some tricks to improve temporal stability, here are some animated gifs showing the conversion of a video clip from each domain to the other:




Now, this process really isn’t very scientific, and it kind of eliminates the freedom to be able to make a note like, “slide that shadow over”, however in certain situations, I think it could come in handy. Although its usability may be limited, this experiment has made me wonder how many other creative applications for unsupervised learning are hiding within the data all around us waiting to be uncovered.
-NeuralVFX