

With the film industry beginning a shift toward virtual production, one of the next places for AI to make an impact is augmented reality. I’ve been curious about this for a while, so I decided to spend some time learning how to build my own AR system from scratch. My journey started with a realtime head pose estimator, however, it quickly evolved into more than that with the help of some machine learning.
A common beginner’s way to perform head pose estimation is to apply a three-step process, which I’ll describe briefly here for anyone who isn’t familiar:
1) Face Bounding Box Detector: Locate the screen space position of faces in an image
2) Landmark Detector: Find the screen space coordinates for 68 landmarks on the face
3) Perspective-N-Point(PnP) Solve: Estimate a 3D matrix which aligns a set of 3D points to a set of 2D points

Using a combination of OpenCV and Dlib, this is possible to get working without too much effort, I even managed to get my test running in Unity on a live video stream. Watching a piece of geometry track a face was exciting at first, however, it didn’t take long for me to start to wonder how you might also track facial expressions in realtime.

Could it be possible to come up with some sort of heuristics based on 2D landmarks, like linking the distance between certain point pairs to blend shape values? Unfortunately, no set of rules I could think of could transform 2D distances into values that made sense in 3D space without becoming unmanageable. However, the reverse is absolutely possible, from a set of blend shape values one could generate an image of a face with ease. So I thought, what if I built this? Could it become the basis for a Neural Net to learn the reverse lookup?
Given a camera matrix, OpenCV is able to convert 3D coordinates into screen space coordinates and render points and lines with an accurate perspective. So if a nice way could be found to draw facial landmarks from a live video feed as line images, and a similar a way could be found to generate an image from a 3D model; then maybe a model trained on the latter could be used to perform inference on the former. To find out, I determined which points on my facial model corresponded to the ones my Landmark Detector used, and I recorded the coordinates for every blend-shape into a JSON file so that I could use python to blend them.

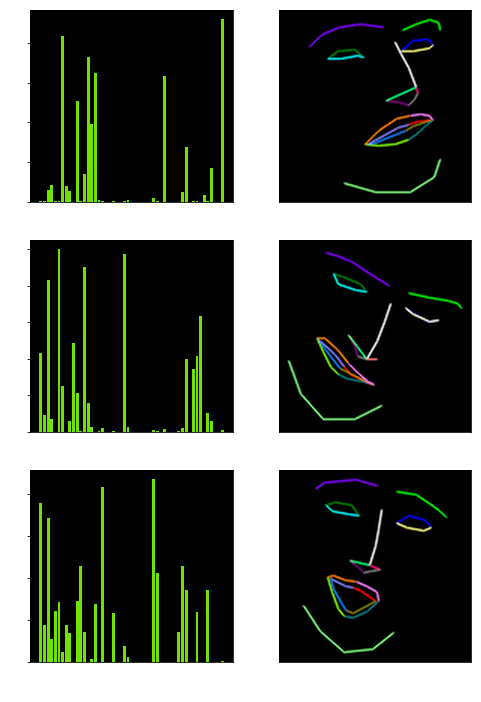
After a bit of experimentation, I was able to get what I needed. Both a Pytorch loader which could render a set of blend-shape values into a line-drawn face and a C++ module which could generate the exact same type of line-drawn face from a live video stream for inference. Since my goal with prediction here is limited to only blend-shape values, I also made sure that my Pytorch loader would draw the face with a slightly different rotation and focal length for every single sample, so that my network would learn to generalize to all perspectives it might see in a video feed.

Since my entire dataset is generated on the fly there wasn’t an actual test that I could use to monitor overfitting numerically, so I had to come up with an alternative way to do this. Samples of a line-drawn face from a video obviously don’t come with a set of blend-shapes, however, I could show them to my Neural Net and ask it to draw a prediction. By comparing the visual difference between the fake and real line-drawn facial expressions every epoch, it was easy to see where the network was failing and succeeding.
For training I handled the problem as regression, trying to get the network to match the blend-shape values as closely as possible, but also added a little trick. Since I had the ability to reconstruct the 3D facial points from a blend-shape, I also measured the distance between the actual points a part of the loss function. For architecture, I experimented with transfer learning, using a couple of different pre-trained models before settling with a Resnet34. This was a bit too complex and overfit at first, but after removing the last several layers of the network, the overfitting was gone and inference time cut in half.
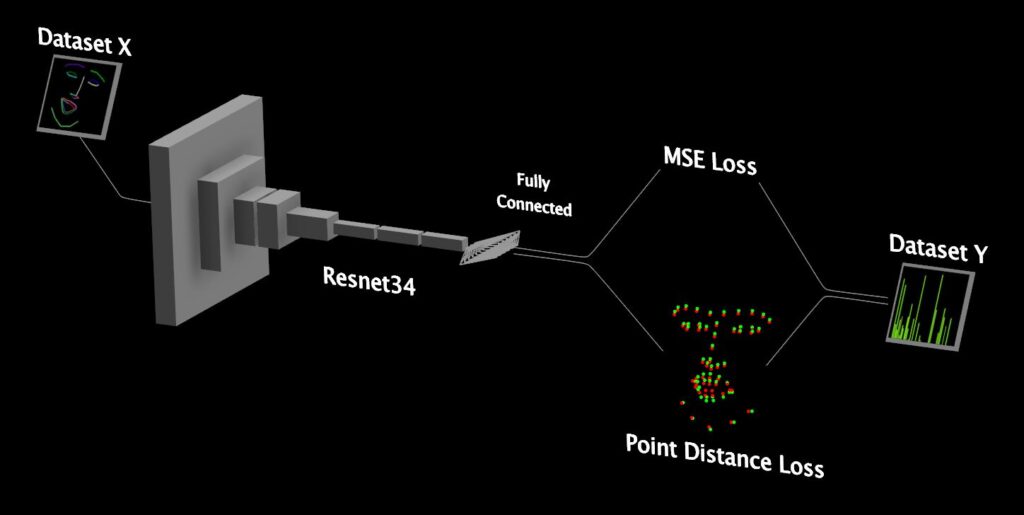
With the model finally converging pretty well, it was time to incorporate it into my realtime pipeline and get it running in Unity. To do this I exported the result as an ONNX model and used OpenCV’s DNN module to load it for inference in C++. The face indeed came right to life, however, there was still one small logic problem with my pipeline. Even though the facial expressions were quite accurate, the face didn’t lock perfectly to the real head, whenever the mouth opened the face would rotate forward a slight bit, causing a bobbing up and down.
The reason for this flaw was from my original setup, which was using a single set of facial points based on a generic face with a closed mouth for my PnP solve. A lot of ideas crossed my mind about how I might get a set of points that could accurately represent the changing face pose, but what I eventually realized was that my Neural Net was already predicting this… Like I did during training in Pytorch, why not use the predicted blend-shape values to generate 3D facial points for the PnP solve also? Details like an open mouth, smiling, squinting and blinking would all be taken into account for no extra calculation.
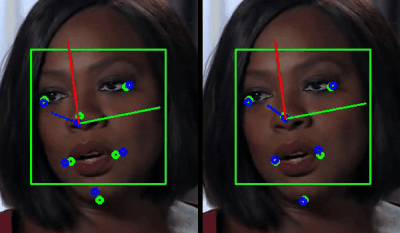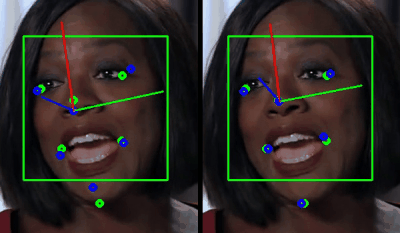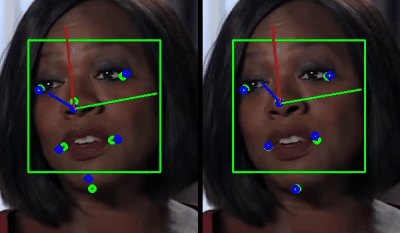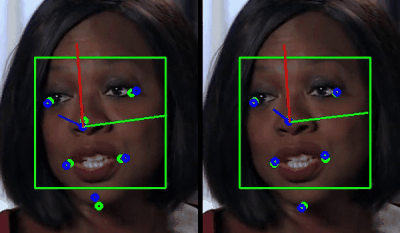
After building this fix for my PnP solve into my C++ module, I booted up my Unity project and found that things ran quite smoothly compared to the previous attempt! ( The render below is actually from Unreal, which I’ve recently ported the project over to )

Although this probably still isn’t quite as good of a solve as your iPhone can do right out of the box, there are many other problems which we face as filmmakers which Google and Apple have no interest in solving. Now that computer vision libraries are getting this comprehensive we don’t need to wait for them anymore, ideas like realtime costume augmentation or on-set motion tracking for whatever animal is the star of your next film are truly solutions that you can build from scratch.
-NeuralVFX