
At some point, most of us have needed to adjust a camera move in 3D. I’ve seen it done every way, from blocking out projection geometry to allow a slight camera nudge, all the way to building an entire photo-real CG set and rendering a different camera path from scratch. A couple of GAN papers have come out this year using simple 3D renders as training data and then using the trained network to generate new views from scratch. These are pretty remarkable, however, I’ve been itching to see if the idea could be applied to real footage.
The idea would be that the filmmaker would take a couple slightly different takes along the camera path they hoped to see, or that maybe the VFX Supervisor could go in and get every angle of the set possible with a drone, after training the network on all that data, you then give the network a brand new camera view and it generates an accurate image. Since I had a couple of unused video clips from my previous light-swapping project, I decided to see if I could concoct an experiment with them.

The video I chose was of a Buddhist statue, taken by waving the camera around the scene to get lots of varying perspectives. In order to provide the network with a way to create new perspectives, I would need a label representing the perspective of each photo. In a 3D scene every camera has a 4×3 world matrix (4 Vectors), a mathematical description of its position and orientation in the world, this is ideal for the neural net to try and convert, because this matrix will never get gimbal lock, and neural networks are quite good at encoding and decoding meaning into and out of meaningful vectors. To extract this data I simply dropped the entire image sequence of the clip into a photo-modeling program and extracted the camera positions of three thousand images. After I got the cameras separated into a test and train set, I wrote a little script to write each matrix-image pair into a CSV file.
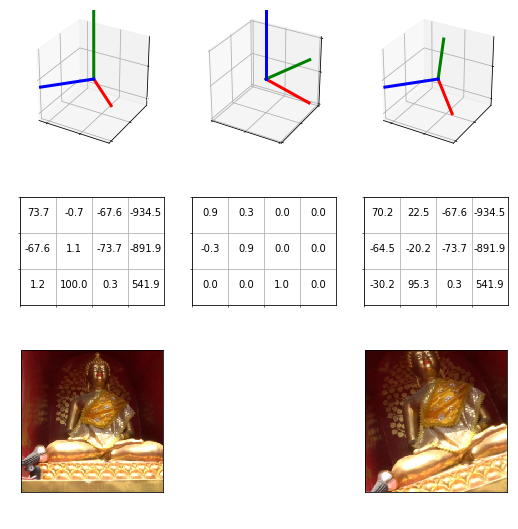
One thing I’ve learned over my experiments to date is that almost every convolutional net trains exponentially better with image augmentation, these are slight rotations, zooms and re-positioning of the image in 2D before it’s fed to the network. However in this case, because the job of the network is to convert the matrix into the image, moving the image around would break the relationship with the matrix we are trying to learn. I figured it was pointless to try and train this without image augmentation, so I decided to tackle the problem by calculating an augmented camera matrix also. What I ended up with was a custom Pytorch data-loader, which randomly picks a rotation and then multiplies the 3D camera matrix by our new rotation while also performing a transform on the photo using the same value. To give it a bit more variance, I also added focal length to the CSV so that I could use this value to represent image scaling.
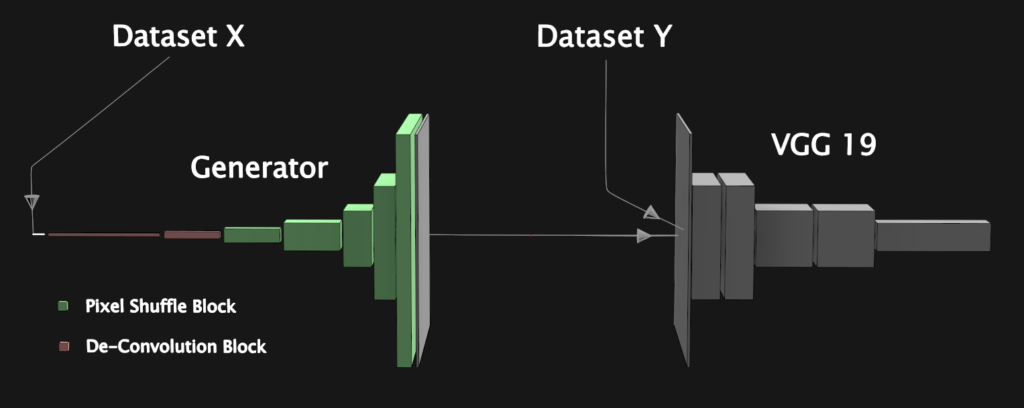
For network architecture, I figured that I would need a de-convolutional generator to convert the matrix to an image, a pre-trained VGG19 network to use as a perceptual loss and maybe a patch discriminator to push it to photo-realism. In order to cut the problem up into smaller more manageable pieces, I decided to focus first on getting as much as physically possible out of my perceptual loss and generator, and then consider introducing a discriminator into the equation.
To understand what the VGG net was seeing, I did some examination of its layers using samples from the dataset. If you take a sample, and then feed both it and a blurry version of it to the network, you can then extract the features of each layer and calculate the difference between them. This, of course, is how you measure perceptual loss, however, if you instead display the result as an image, it’s a way to simulate what the network might see during training. Now armed with a bit of a visual guide to work with, I made a wedge of a couple epochs with different weights per layer based on my assumptions, and also varying amounts of L1 pixel loss. It turned out that if any of the layers above layer 12 were included it would cause inconsistent “imaginary details” to start showing up in the image, which kind of makes sense when looking at how noisy the higher layers look, another important thing I noticed was that neither L1 nor perceptual loss looked too impressive on their own, but paired together they appear to help one another.

Recently, pixel shuffling has become a popular tool in image enhancement as an alternative to de-convolution, so as another attempt to improve image quality I decided to try adding some in my generator. At first I tried replacing every de-conv layer, unfortunately, this just made everything so blurry that it was unrecognizable. What I learned by playing around was that the first two de-conv operations, which stretch the camera matrix to a 1024 and then 512 filter tensor, worked better as de-conv. With that change implemented, in early training all the images became incredibly smooth yet not without detail, and near the end, the results did indeed start to look much more crisp than before.
During initial training, I used dropout of .1 inside of each up-res block of the generator and weight decay of 1e-05, which is my usual combination to prevent over-fitting, however after lowering them to .01 and 1e-06 I was surprised to see that it still was not over-fitting and the result became even sharper.
Here are some results generated using matrices from the test set, which are almost a whole foot away from any sample within the training set:
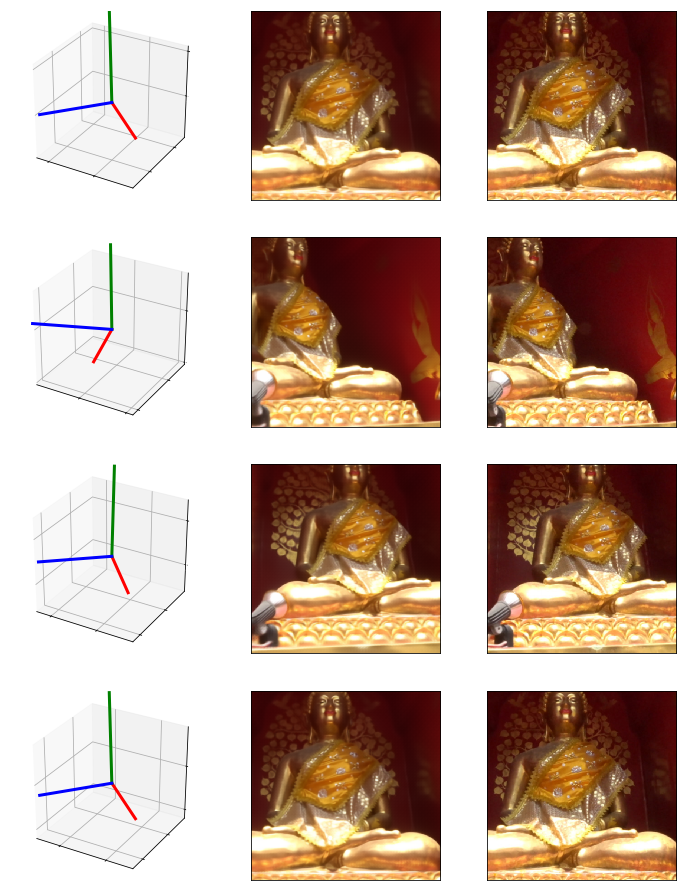
From looking at the resulting images, I would surmise that the network isn’t just generating a “nearest neighbor”, which would just kind of blend the closest images from the training set. In order to get this perspective right on a view it’s never seen, the network appears to have taken the smart path and learned the properties of 3D space from the input matrix.
To test out the temporal coherence of the network, I animated a brand new camera in Maya and wrote out a new CSV file of camera matrices. Here is the resulting animation after feeding the CSV to the network:

The result is still a bit soft and you can see a tiny amount of buzzing on the head, however, I’m confident there are ways to overcome this. Seeing that the idea basically works, imagine how many other vectors are sitting around in your production pipeline waiting to be converted to an image? Ideas like mocap to video conversion, or converting scene layout descriptions into navigable photo-real environments could really work, and they might be here sooner than we expect.
-NeuralVFX