
Every great ML model is built on a foundation of great data, but creating it is often a soul-crushing chore. Several months ago I was handed a large piece of media, over an hour in length and asked to build a dataset for fine-tuning a stable diffusion model. I knew a couple thousand carefully chosen images could make a better dataset than a hundred thousand poorly chosen ones, but which ones? After running through this process multiple times, here’s the pipeline that emerged in the end. For demonstration purposes, I’ve used a long compilation of clips of ‘Jurassic World’ from YouTube for this post.
Selecting Sharp Images
My first attempt at making an initial frame selection was far too primitive, I would grab every Nth frame from the video clip arbitrarily. Unfortunately, half the frames of an average film are heavily motion blurred or out of focus, and these caused blurriness to become part of the distribution of the models I trained.

Laplacian variance is a great mathematical measure of image sharpness in OpenCV, so I decided to use this to find the crisp frames. Of course on certain shots, every single frame might be crisp, so to get a uniform sampling across the whole piece of media, I took each second of footage, and fetched the frame with the highest Laplacian variance within that second.
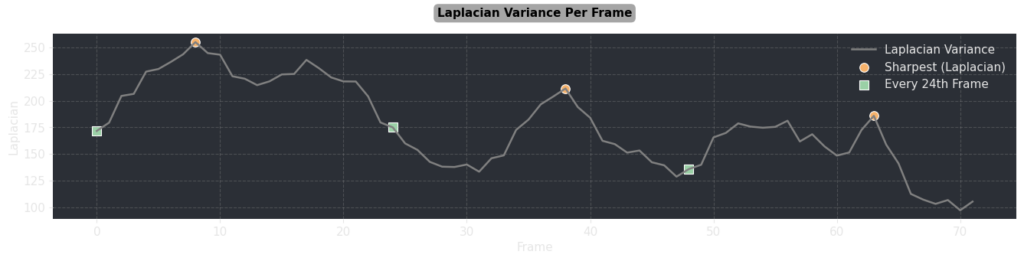

The chart above shows the Laplacian variance plotted, you can see the points selected are the highest value across the local time range, and the images selected have much less blur than the initial arbitrary selection. For my ‘Jurassic World’ dataset, running this on my whole piece of media gave me my first 4,000 sharp images to work with.
Content Based Filtering
Across a whole piece of media there are bound to be certain types of images which aren’t helpful for fine-tuning a model, like in this example, images without dinosaurs. In this case, if the model starts trying to re-learn what humans look like, all human prompts will start to look like actors from ‘Jurassic World’, and we lose flexibility. My initial approach to deal with filtering these, was to manually thumb through the images and cull out the ones which wouldn’t be helpful. However, requirements would change without warning during the course of the project, costing me days of labor each time.
Previously I’d had some great success with using multimodal LLMs for labeling images, so I decided to see if I could also use them to deal with this filtering step. All I needed was to be able to formulate a yes or no question, which could correctly answer whether the image belonged in the dataset. All the images could then be looped through, and fed to the LLM along with that question, and if the criteria were not met, the image would be thrown out.
In this case I used:
You are an image analyzer, your job is to look at an image and answer a YES or NO question.
Your question is:
Does the image primarily contain dinosaurs or reptilian creatures which are large in frame?
Answer <YES> or <NO>Getting the prompt right took a bit of experimentation, but after running this filter on my test dataset, my image count was cut by about half, down to about 2,000 images. Here are some random samples showing how the filter divided the content:
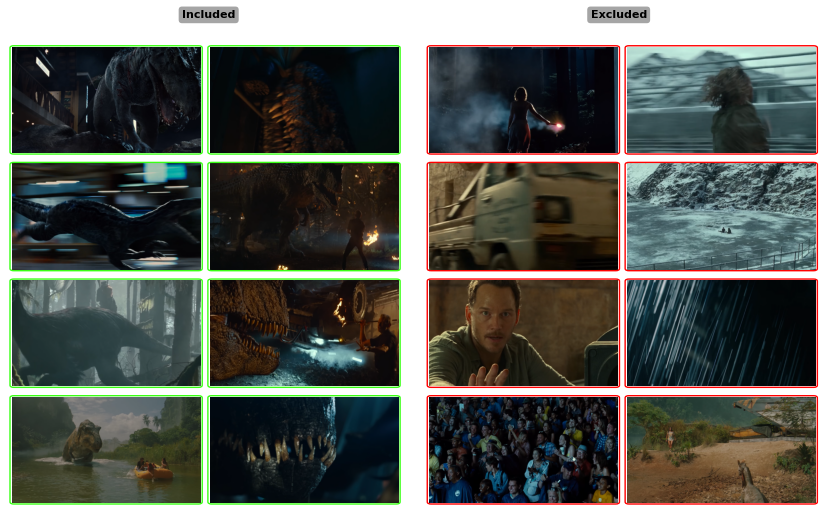
There were a couple stragglers which it got wrong, however, at this stage what’s most important is being able to test the broad brush strokes as quickly as possible. With this being fully automated, it’s possible to test several alternative theories about what data selection might make the best model, let them train over a weekend, and evaluate. Once that’s determined, there’s always room for manual curation later.
De-Duplication
The third major issue which kept coming up, is that the fine-tuned model would often output a very specific pose for the creature I was training on. Sometimes in film and TV, the same angle is used several times in a scene, or occasionally there’s just a slow shot where nothing much moves. The result was that my dataset had tons of clusters of images, which were 90% the same. This isn’t healthy because the model tries to learn this distribution during training, and thus it learns to generate the duplicate ones disproportionately compared to others.
CLIP image embeddings are useful for comparing semantics between images mathematically, and are a perfect tool for finding similar images. For me to get a visual understanding of which images in the dataset might have the most duplicates, I decided to use UMAP, which can convert the 512 dimension vector into a 2D space, making it possible to visualize in a 2D plot. This way by looking for clumps of images grouped together on the plot, I could understand which parts of the media had the most duplicates, and visualize different techniques of de-duplication.
The technique I eventually found to work best was an iterative one. I set a distance threshold in CLIP space and counted how many neighbors each image had underneath that threshold ( visualized in red below ), then iteratively cycled through the samples which had the most neighbors, and pruned them one at a time. One option I found to improve this, was to make sure that I pruned the one with the lowest Laplacian variance, this way the sample which is left representing each cluster would be the highest quality.

With the dataset crisp, on-topic and de-duplicated, the final count for the ‘Jurassic World’ dataset came to about 1,500 images. Most importantly since each step is procedural, it will be easy to iterate when requirements change. Testing off-the-cuff ideas like, “remove all nighttime shots”, or adjusting the tolerance for blurriness or de-duplication can be done at the drop of a hat.
A model is only as good as the data it learns from. By turning the overwhelming chore of data selection into an automated pipeline, you spend less time sifting through frames and more time doing what matters: bringing your creative vision to life.
-NeuralVFX