
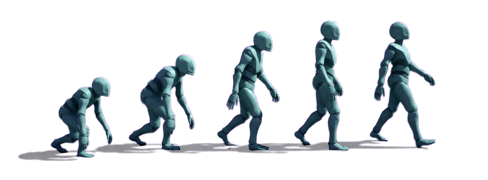
Over the years I’ve seen many demos of reinforcement learning, where you can teach an agent how to navigate a 2D or 3D environment in search of rewards, while learning how to adapt to physics and obstacles along the way. With modern tools for training reinforcement learning agents now built directly into both Unity and Unreal Engine, I wondered: are these tools strong enough to generate physically plausible character motion? I decided to crack open Unreal Engine and find out.
My first step was to go through the tutorial on Epic’s website, which details how to train a car to race around a track using reinforcement learning. I got an elementary understanding of how the system worked, and started exploring how to apply it to a humanoid character. Unreal’s physics ragdoll system turned out to be perfect for this. It’s typically used to make a lifeless character collapse on the ground naturally, but each limb’s rotation can also be driven and animated while still properly reacting to physics.

For my first real test, I set out to teach it to balance. The setup included exposing the rotation, velocity, and position of each bone as inputs to the neural network; and connecting the network’s output to the rotation of each physics joint constraint. As a reward I used a dot product to measure how far the head joint deviated from being directly above the center of the feet, and I set up a trigger for early termination when the torso hit the floor, to prevent long episodes of the ragdoll struggling in a collapsed state.
With my Unreal scene set up to train 16 agents in parallel, I kicked it off. Initially they all flailed their limbs randomly while collapsing to the ground, and not much changed for a couple hours. But this process is supposed to be notoriously slow, so I left it running and went to sleep. When I woke up, it was like Christmas morning. All the agents were miraculously standing upright, demonstrating a primitive technique they had learned to kind of wobble around in place that kept them balanced.

With this first success, walking now felt within reach. To address the wobbling I built a penalty based on overall limb velocity, and to encourage walking I added a reward based on heading and proximity to a target object. My hope was that these would layer naturally on top of the balancing reward. Starting from my balancing checkpoint I let it train for a whole day, but every attempt it made to break from the balancing pose resulted in falling. It had learned so much about balancing that any new action would reduce this reward before gaining another, leaving it completely stuck.
So I scrapped the checkpoint and retrained with the new rewards from scratch. When I came back the next day, the character had learned to cross its legs and roll around, smacking its hands on the ground. Although it was impressive in its own right, it wasn’t exactly the locomotion I had in mind…

This was a textbook example of reward hacking. Chasing the new rewards all at once was too difficult, so it chased whatever temporary increase in the reward it could find, in this case by tying its legs into a pretzel shape.
This strategy alone wasn’t going to result in a walking character. Unfortunately, shaping simplistic rewards is no match for the complexity of human locomotion. During my initial research, one paper that had caught my interest was “Deep Mimic” from 2018, which outlines a training setup and a set of reward functions specifically designed to help an agent learn motions from reference animation. Initially, I thought this was overcomplicated for my goal, but given the state of my experiment, I decided now was the time to start looking into it. There was just one snag: they use thousands of pre-recorded motion clips which I don’t have access to, and wouldn’t match the rig I’m using anyway.
However, an alternative strategy came to me: Unreal’s control rig. Rather than use thousands of clips, I could use the control rig as data augmentation, to turn one clip into many. So I built a control rig with the ability to walk and even chase down a goal object; adjusting its footsteps based on speed and the amount of turning. And just like that, I had an entire distribution of walking animation to train on.

The tricks which Deep Mimic uses to replicate a walk cycle are twofold. First, a set of reward functions are used to enforce pose matching, quantifying the difference in rotation and velocity of each joint, plus the positions of the feet and hands. Second, they present a technique called Reference State Initialization (RSI), which initiates each episode of training using an actual pose + velocity from the walk cycle, and rewards it for continuing the motion correctly. What’s elegant about this is that once it’s able to predict the correct motion for the next couple ticks from each point in the cycle, it basically understands the whole cycle.
My first test with the Deep Mimic rewards setup was encouraging: the character would start with the right pose and even make it into its first step, but it would usually fall over before the second step could start. However, compared to my prior test, the character didn’t appear to adjust its center of gravity to maintain balance. This made perfect sense. The motion it was replicating was a generic retargeted cycle, and probably wasn’t realistically balanced to begin with; just following this motion wouldn’t automatically encourage balance.
I decided to reintroduce the balance reward from my initial test, and the difference was profound. By the next day something resembling walking started to emerge. I let it continue training for another couple of days, and although it improved to the point of walking several steps, the posture didn’t match the reference animation and the movement was still volatile; it was still finding ways to collect reward while partially avoiding the original goal. I needed other tricks to push it over the finish line.

The imitation learning system in Learning Agents allows you to record the observations and actions of any actor, and use this to train a model the old-fashioned way. Just memorizing the exact actions you want the actor to perform, without any consideration of environment interaction or physics. I wondered if I could use this for my initial weights to replicate the human posture, and then fine-tune the physics of balancing from there with reinforcement learning. So I connected up my control rig and recorded several minutes of animation, following the goal object as it meandered back and forth around the scene.
The next step is to actually train the weights based on the motion in the recording. There’s really no limit to how long you can train for, so for my first run I let it run for an hour. After running reinforcement learning from those weights, the results were not promising at all. The model would spawn and immediately fall over, appearing to be stuck in whatever pose it had been born in. It had been pre-trained so deeply into pose matching that it could not escape.
So I decided to run a wedge of different amounts of imitation pre-training, several different durations from 1 minute to 45, and then kicked off reinforcement learning from each one. The next day, almost all of the simulations were still stuck in a rut, however one of the tests with a minimal amount of pre-training was beginning to walk. As it turns out, all it needed was just a little sprinkle of suggestion, to steer the training down the proper path. I let this one train for a week, and as you can see below, not only did it learn to walk, but it could adapt and change direction as the goal moved.

The big lesson here is that Learning Agents out of the box may not achieve human motion, but reading papers, and applying lessons from past research, can get you pretty close. Each year better techniques are published, and many of them can be implemented in Learning Agents almost completely in blueprints.
This use case is really a toy example, but seeing it come together so quickly has stoked my enthusiasm. The potential use cases are endless, from physics constrained animation retargeting, to crowd simulation with a new level of physical accuracy. As reinforcement learning is democratized, we can look forward to far fewer barriers standing in the way of physically realistic animation.
-NeuralVFX
Really good stuff man! Now get it run haha
It’s amazing that this is powered by machine learning. I love that it’s trained with penalties and reward – it’s like dog training but with a much more simple mind. I’m excited to see where the future takes us – it would be awesome to have this as a ‘helper’ in terrain locomotion. (Beyond what IK does for us now)